一、CANE [2017]
《CANE: Context-Aware Network Embedding for Relation Modeling》
network embedding: NE(即network representation learning: NRL)旨在根据顶点在网络中的结构角色 (structural role) ,从而将网络的顶点映射到低维空间中。network embedding提供了一种高效(efficient) 且有效 (effective) 的方法来表达和管理大型网络,缓解了传统基于符号的representation的计算问题和稀疏性问题。因此,近年来network embedding吸引了人们的许多研究兴趣,并在包括链接预测、顶点分类、社区检测在内的许多网络分析任务上取得了可喜的表现。在现实世界的社交网络中,一个顶点在与不同的邻居顶点交互时可能表现出不同的方面(
aspect),这是很直观的。例如,研究人员通常与各种合作伙伴就不同的研究主题进行合作(如下图所示),社交媒体用户与分享不同兴趣的各种朋友联系,一个网页出于不同目的链接到多个其它网页。然而,现有的大多数network embedding方法只为每个顶点安排一个single embedding向量,并产生以下两个问题:这些方法在与不同邻居交互时,无法灵活转换不同的方面(
aspect) 。在这些模型中,一个顶点倾向于迫使它的所有邻居之间的
embedding彼此靠近,但事实上并非一直如此。例如下图中,左侧用户和右侧用户共享较少的共同兴趣,但是由于他们都链接到中间用户,因此被认为彼此接近。因此,这使得顶点embedding没有区分性。即:“朋友的朋友“ 不一定是朋友。
为了解决这些问题,论文
《CANE: Context-Aware Network Embedding for Relation Modeling》提出了一个Context-Aware Network Embedding: CANE框架,用于精确建模顶点之间的关系。更具体而言,论文在信息网络(information network)上应用CANE。信息网络的每个顶点还包含丰富的外部信息,例如文本text、标签label、或者其它元数据meta-data。在这种场景下,上下文的重要性对network embedding更为关键。在不失一般性的情况下,论文在基于文本的信息网络中实现了CANE,但是CANE可以很容易地扩展到其它类型的信息网络。在传统的
network embedding模型中,每个顶点都表达为一个静态的embedding向量,即context-free embedding。相反,CANE根据与当前顶点交互的不同邻居,从而将动态的embedding分配给当前顶点,称为context-aware embedding。以一个顶点context-free embedding保持不变;而当面对不同的邻居时,context-aware embedding是动态的。CANE类似于GAT,其中不同邻域顶点的attention权重是不同的。在CANE中,注意力权重是hard的(0或者1);在GAT中,注意力权重是soft的(0到1之间)。当顶点
context embedding分别来自它们的文本信息。对于每个顶点,我们可以轻松地使用神经模型(neural model),例如卷积神经网络和循环神经网络来构建context-free embedding和text-based embedding。为了实现context-aware text-based embedding,论文引入了selective attention方案,并在这些神经模型中建立了mutual attention)。mutual attention预期引导神经模型强调那些被相邻顶点focus的单词,并最终获得context-aware embedding。每个顶点的context-free embedding和context-aware embedding都可以通过使用现有的network embedding方法学到(如DeepWalk,LINE,node2vec)并拼接起来。论文对不同领域的三个真实数据集进行了实验。与其它
SOTA方法相比,链接预测的实验结果展示了论文框架的有效性。结果表明,context-aware embedding对于网络分析至关重要,特别是对于那些涉及顶点之间复杂交互的任务,如链接预测。论文还通过顶点分类和案例研究来探索论文框架的性能,这再次证实了CANE模型的灵活性和优越性。CANE在链接预测方面比SOTA方法取得了显著的提升,在顶点分类方面与SOTA方法的性能相当。相关工作:随着大型社交网络的快速增长,
network embedding(即network representation learning)已被提出作为网络分析任务的关键技术。近年来,人们已经提出了大量的
network embedding模型来学习有效的顶点embedding。例如:DeepWalk在网络上执行随机游走,并引入了一种有效的word representation learning模型SkipGram来学习network embedding。LINE优化大型网络中edge的联合概率和条件概率,从而学习顶点representation。node2vec将DeepWalk中的随机游走策略修改为有偏的随机游走(biased random walk),从而更有效地探索网络结构。
然而,这些
network embedding模型中的大多数仅将结构信息编码为顶点embedding,而没有考虑现实世界社交网络中伴随顶点的异质信息(heterogeneous information)。为解决这个问题,研究人员努力将异质信息整合到传统的network embedding模型中。例如:text-associated Deep-Walk: TADW使用文本信息改进了基于DeepWalk的矩阵分解。max-margin DeepWalk: MMDW利用顶点的labeling信息来学习network representation。group enhanced network embedding: GENE整合了NE中存在的group信息。context-enhanced network embedding: CENE将文本内容视为一种特殊的顶点,并同时利用结构信息和文本信息来学习network embedding。
据我们所知,所有现有的
network embedding模型都聚焦于学习context-free embedding,但是忽略了顶点和其它顶点交互时的不同角色。相比之下,我们假设一个顶点根据与它交互的不同顶点而具有不同的embedding,并提出CANE来学习context-aware embedding。
1.1 模型
1.1.1 问题定义
我们首先给出一些基本的符号和定义。给定信息网络(
information network)network representation learning旨在根据网络结构和关联信息(如文本和label)为每个顶点embeddingrepresentation空间的维度。Context-free Embedding的定义:传统的network representation learning模型为每个顶点学习context-free embedding。这意味着顶点的embedding是固定的,并且不会根据顶点的上下文信息(即与之交互的另一个顶点)而改变。Context-aware Embedding的定义:与现有的、学习context-free embedding的network representation learning模型不同,CANE根据顶点不同的上下文来学习该顶点的各种embedding。具体而言,对于边CANE学习context-aware embeddingCANE的模型容量要比传统的network representation learning模型容量大得多。传统network representation learning模型只需要计算embedding,而CANE模型需要计算embedding。更大的模型容量可能会导致严重的过拟合。此外,
CANE模型中每个顶点有可变数量的embedding,在顶点分类任务中,如何利用这些embedding是个难点。
1.1.2 模型
整体框架:为了充分利用网络结构和关联的文本信息,我们为顶点
embedding:基于结构(structure-based) 的embeddingtext-based的embeddingstructure-basedembeding可以捕获网络结构中的信息,而text-based embedding可以捕获关联文本信息中的文本含义(textual meaning)。使用这些embedding,我们可以简单地拼接它们并获得顶点embedding为CANE并不是独立建模structure-basedembeding和text-based embedding,而是联合优化它们。注意,
text-based embeddingcontext-free的、也可以是context-aware的,这将在后面详细介绍。当context-aware时,整个顶点embeddingcontext-aware。通过上述定义,
CANE旨在最大化所有edge上的目标函数,如下所示:这里每条
edge的目标函数其中:
structure-based objective),text-based objective)。接下来我们分别对这两个目标函数进行详细介绍。CANE仅建模一阶邻近性(即观察到的直接链接),并没有建模高阶邻近性,因为CANE隐含地假设了 “朋友的朋友“ 不一定是朋友。仅建模一阶邻近性会遇到数据稀疏的不利影响。基于结构的目标函数:不失一般性,我们假设网络是有向的,因为无向边可以被认为是两个方向相反、且权重相等的有向边。因此,基于结构的目标函数旨在使用
structure-based embedding来衡量观察到一条有向边的对数似然log-likelihood,即:遵从
LINE,我们将上式中的条件概率定义为:基于文本的目标函数:现实世界社交网络中的顶点通常伴随着关联的文本信息。因此,我们提出了基于文本的目标函数来利用这些文本信息,并学习
text-based embedding。基于文本的目标函数
其中:
如果仅仅最小化
这里构建了
structure-based embedding、text-based embedding之间的桥梁,使得信息在结构和文本之间流动。
上式中的条件概率将两种类型的顶点
embedding映射到相同的representation空间中,但是考虑到它们自身的特点,这里并未强制它们相同。类似地,我们使用softmax函数来计算概率,如公式structure-based embedding被视为parameter,与传统的network embedding模型相同。但是对于text-based embedding,我们打算从顶点的关联文本信息中获取它们。此外,text-based embedding可以通过context-free的方式、或者context-aware的方式获取。接下来我们将详细介绍。Context-Free Text Embedding:有多种神经网络模型可以从单词序列word sequence中获取text embedding,如卷积神经网络CNN、循环神经网络RNN。在这项工作中,我们研究了用于文本建模的不同神经网络,包括CNN、Bidirectional RNN、GRU,并采用了性能最好的CNN。CNN可以在单词之间捕获局部语义依赖性(local semantic dependency)。CNN以一个顶点的单词序列作为输入,通过lookup、卷积、池化这三层得到基于文本的embedding。lookup:给定一个单词序列lookup layer将每个单词word embeddingembedding序列word embedding的维度。卷积:
lookup之后,卷积层提取输入的embedding序列local feature。具体而言,它使用卷积矩阵其中:
word embedding拼接得到的矩阵。bias向量。
注意,我们在单词序列的边缘添加了零填充向量。
最大池化:为了获得
text embedding其中:
max是在embedding维度上进行的,tanh为逐元素的函数。
Context-Aware Text Embedding:如前所述,我们假设顶点在与其它顶点交互时扮演不同的角色。换句话讲,对于给定的顶点,其它不同的顶点与它有不同的焦点,这将导致context-aware text embedding。为了实现这一点,我们采用
mutual attention来获得context-aware text embedding。mutual attention使CNN中的池化层能够感知edge中的顶点pair,从而使得来自一个顶点的文本信息可以直接影响另一个顶点的text embedding,反之亦然。加权池化,权重来自于当前顶点文本内容和另一个顶点文本内容的相关性。
如下图所示,我们说明了
context-aware text embedding的生成过程。给定一条边attentive matrix)correlation matrix)注意,
pair-wise相关性得分 (correlation score) 。然后,我们沿importance vector),分别称作行池化(row-pooling)和列池化(column-pooling)。根据我们的实验,均值池化的性能优于最大池化。因此,我们采用如下的均值池化操作:其中:
接下来,我们使用
softmax函数将重要性向量attention vector即:对重要性向量进行
softmax归一化。最后,顶点
context-aware text embedding计算为:现在,给定一条边
context-aware embedding,它是structure embedding和context-aware text embedding的拼接:其中

CANE优化过程:如前所述,CANE旨在最大化若干个条件概率。直观而言,使用softmax函数优化条件概率在计算上代价太大。因此,我们使用负采样,并将目标函数转换为以下形式:其中:
sigmoid函数,out-degree。之后,我们使用
Adam来优化新的目标函数。注意,CANE通过使用训练好的CNN来为新顶点生成text embedding,从而完全能够实现zero-shot场景。
1.2 实验
为了研究
CANE对顶点之间关系建模的有效性,我们在几个真实世界的数据集上进行了链接预测实验。此外,我们还使用顶点分类任务来验证顶点的context-aware embedding是否可以反过来组成高质量的context-free embedding。数据集:我们选择如下所示的、真实世界的三个数据集。
Cora:一个典型的论文引用网络数据集。在过滤掉没有文本信息的论文之后,网络中包含2277篇机器学习论文,涉及7个类别。HepTh:另一个论文引用网络数据集。在过滤掉没有文本信息的论文之后,网络中包含1038篇高能物理方面的论文。Zhihu:一个大型的在线问答网络,用户可以相互关注并在网站上回答问题。我们随机抽取了10000名活跃用户,并使用他们关注主题的描述作为文本信息。
这些数据集的详细统计信息如下表所示。

baseline方法:我们采用以下方法作为baseline:仅考虑网络结构:
Mixed Membership Stochastic Blockmodel: MMB: 是关系数据的一个传统图模型,它允许每个顶点在形成边的时候随机选择一个不同的topic。DeepWalk:使用截断的随机游走将图结构转化为线性结构,然后使用层次softmax的SkipGram模型处理序列从而学习顶点embedding。LINE:分别定义损失函数来保留一阶邻近性和二阶邻近性来求解一阶邻近representation和二阶邻近representation,然后将二者拼接一起作为representation。Node2Vec:通过一个有偏随机游走过程(biased random walk procedure) 来将图结构转化为线性结构,然后使用层次softmax的SkipGram模型处理序列。
同时考虑结构和文本:
Naive Combination:用两个模型分别计算structure embedding和text embedding,然后简单地将structure embedding和text embedding拼接起来。TADW:采用矩阵分解的方式将顶点的文本特征融合到network embedding中。CENE:将文本内容视为一种特殊的顶点来利用结构和文本信息,并优化异质链接的概率。
评估指标:对于链接预测任务,我们采用标准的评估指标
AUC。对于顶点分类任务,我们采用L2正则化的逻辑回归来训练分类器,并评估分类准确率指标。训练配置:
为公平起见,我们将所有方法的
embedding维度设为200。对于
LINE方法,负采样系数设置为5。一阶embedding和 二阶embedding维度都是100维,使得拼接后的向量有200维。对于
node2vec方法,我们使用网格搜索并选择最佳的超参数。对于
CANE方法,我们通过超参数搜索选择最佳的为了说明文本
embedding以及注意力机制的效果,我们设计了三个版本:CANE with text only:仅包含context-aware text embedding。CANE without attention:包含structure embedding以及context-free text embedding。CANE:完整的CANE模型。
链接预测实验:我们分别移除了
Cora,HepTh,Zhihu等网络不同比例的边,然后评估预测的AUC指标。注意,当我们仅保留5%的边来训练时,大多数顶点是孤立的,此时所有方法的效果都较差而且毫无意义。因此我们不考虑5%以下比例的情况。Cora的结果如下,其中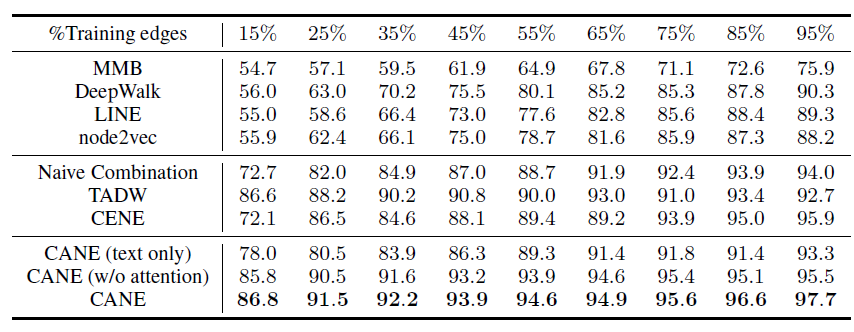
HepTh的结果如下,其中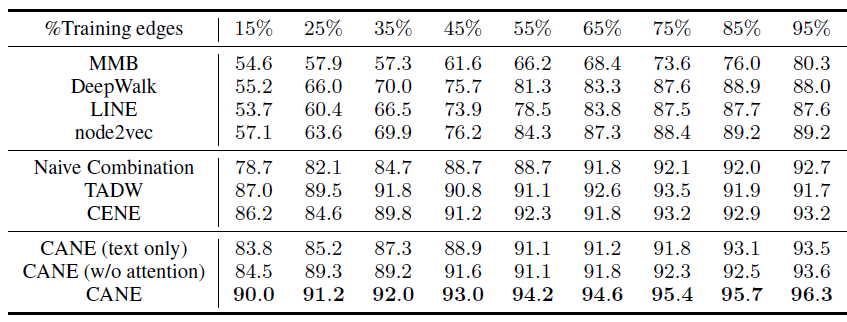
Zhihu的结果如下,其中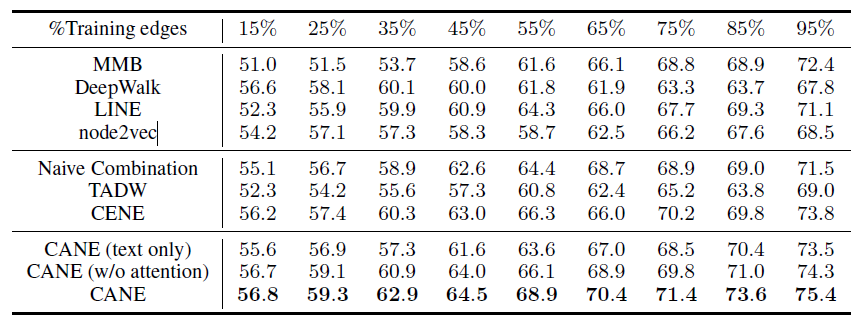
从链接预测任务的实验结果可以看到:
CANE在所有训练集、所有训练比例都取得最好的效果,这表明CANE在链接预测任务中的有效性,验证了CANE具备精确建模顶点之间关系的能力。在不同的训练比例下,
CENE和TADW的效果不稳定。具体而言:CENE在训练比例较小时效果比TADW较差,因为相比TADW,CENE使用了更多的参数(如卷积核和word embedding),因此CENE需要更多的训练数据。与
CENE不同,TADW在较小的训练比例时表现得更好,因为基于DeepWalk的方法即使在边有限的情况下也可以通过随机游走很好地探索稀疏网络结构。然而,由于它的简单性和bag-of-words假设的局限性,TADW在较大的训练比例时表现不佳。CANE在各种情况下,效果都很稳定。这展示了CANE的灵活性和鲁棒性。
通过引入注意力机制,学到的
context-aware embedding比没有注意力的embedding效果更好。这验证了我们的假设:顶点和其它顶点交互时应该扮演不同的角色,从而有利于相关的链接预测任务。
综上所述,以上所有实验结果表明:
CANE可以学习高质量的context-aware embedding,这有利于精确估计顶点之间的关系。此外,实验结果也表明了CANE的有效性和鲁棒性。实验可以看到:引入顶点的文本信息可以更好地提升
network embedding的质量。因此,CANE应该和带文本信息的baseline方法进行比较。如果CANE和DeepWalk/LINE/node2vec等纯结构的network embedding方法比较,则不太公平。顶点分类实验:网络分析任务(如顶点分类和聚类)需要得到该顶点的整体
embedding,而不是顶点的很多个context-aware embedding。为了得到整体embedding,我们简单的将每个顶点的所有context-aware embedding取平均,如下所示:其中
context-aware embedding数量。使用生成的整体
embedding,我们在Cora数据集上执行顶点分类任务,采用2-fold交叉验证并报告平均准确率。实验结果如下图所示,可以看到:CANE的性能与SOTA的CENE相当。这表明:学到的context-aware embedding可以通过简单的取平均操作转化为高质量的context-free embedding,并进一步应用于其它网络分析任务。通过引入
mutual attention机制,CANE的性能比没有注意力的版本得到较大的提升。这与链接预测的结果是一致的。
综上所述,实验结果表明
CANE可以灵活地完成各种网络分析任务。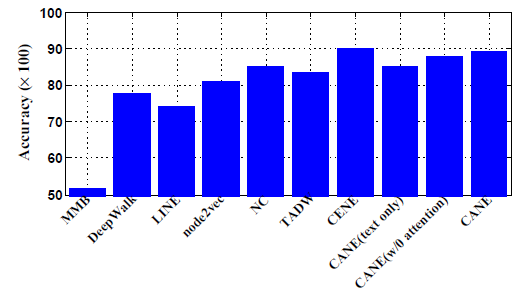
案例研究:为了说明
mutual attention机制从文本信息中选择有意义特征的重要性,我们可视化了两个顶点的热力度。图中,每个单词都带有各种背景色,颜色越深该单词的权重越大。每个单词的权重根据注意力权重来计算,计算方式为:首先,对于每对顶点
pair,我们获取其单词序列每个卷积窗口的注意力权重然后,在这个窗口内我们为每个单词分配注意力权重(窗口内的多个单词对应于该窗口的权重)。
最后,考虑到一个单词可能会出现在多个窗口内(单个顶点的单词序列包含很多个窗口),我们将该单词的多个权重相加,得到单词的注意力权重。
我们提出的注意力机制使得顶点之间的关系明确且可解释。如下图所示,我们选择
Cora数据集存在引用关系的三篇论文A,B,C。可以看到:尽管论文B,C和论文A存在引用关系,但是论文B和论文C关注的是论文A的不同部分:Edge #1在论文A上重点关注reinforcement learning。Edge #2在论文A上重点关注machine learning, supervised learning algorithms,complex stochastic models。
另外,论文
A中的所有这些关键元素都可以在论文B和论文C中找到对应的单词。这些关键元素对引用关系给出了准确的解释,这很直观。这些挖掘出的顶点之间显著的相关性,反应了mutual attention机制的有效性,同时也表明CANE精确建模关系的能力。